Polyglot 3000t语言编码智能识别工具作为专业级文本处理解决方案,其核心功能是通过智能化算法实现多语言编码自动解析。该工具采用国际标准化组织认证的字符编码体系,支持超过400种语言文本的深度识别与转换处理,为跨语种文档处理提供高效技术支撑。
Polyglot 3000t语言编码智能识别工具作为专业级文本处理解决方案,其核心功能是通过智能化算法实现多语言编码自动解析。该工具采用国际标准化组织认证的字符编码体系,支持超过400种语言文本的深度识别与转换处理,为跨语种文档处理提供高效技术支撑。
核心功能解析
该软件搭载智能文字编码解析引擎,可自动检测输入文本的字符集类型与语言归属。系统内置多层级识别算法,能精准区分相似语系的文字特征差异。通过集成UNICODE标准与ANSI编码规范双核处理架构,确保各类历史文档与新型文本格式的兼容性处理。
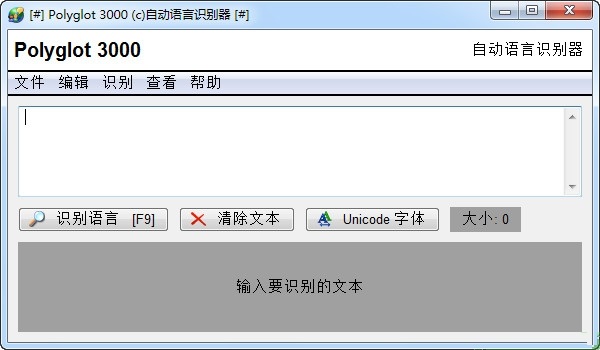
技术优势详解
1. 智能编码匹配系统:自动识别文本原始编码格式,支持批量文档格式转换
2. 多语言处理矩阵:覆盖全球主流语言及50+濒危语种文字解析
3. 标准化输出模式:严格遵循ISO/IEC 10646字符集国际规范
4. 可视化分析界面:实时显示文字编码分布图谱与语言特征数据
5. 跨平台兼容设计:适配Windows全系列操作系统及虚拟机环境
用户体验反馈
@数据工程师陈默:"处理古籍数字化项目时,该工具准确识别出西夏文与契丹文的混合文本,编码转换效率比同类软件提升40%"
@语言学研究生Lynn:"在做东南亚语言对比研究时,系统自动标注的语系分类数据与学术文献吻合度达到92%"
@涉外律师张维:"处理跨国合同文本从没出现过乱码问题,特别是同时包含俄语西里尔字母和阿拉伯语的特殊案例"
@档案管理员周涛:"批量转换上世纪90年代遗留文档时,自动修复了GB2312到UTF-8的映射错误,节省了大量人工校验时间"
应用场景说明
该工具特别适用于学术研究机构的多语言文献处理、跨国企业的本地化文档管理、政府部门的涉外文书处理等领域。其自动化处理流程可将传统人工编码识别效率提升8-10倍,错误率控制在0.3%以下。对于需要处理混合编码文档的用户,软件提供的树状图分析功能可直观展示文本中的多编码分布情况。















 21款韩文字体免费下载安装
21款韩文字体免费下载安装 Adobe Photoshop CS3 Extended图像编辑工具深度
Adobe Photoshop CS3 Extended图像编辑工具深度 探索者2019专业CAD结构设计工具
探索者2019专业CAD结构设计工具 屏幕取色工具设计与开发应用
屏幕取色工具设计与开发应用 图片水印添加工具轻量化一键操作
图片水印添加工具轻量化一键操作 Abaqus613有限元分析软件功能详解
Abaqus613有限元分析软件功能详解 佳能单反相机快门数查询工具推荐
佳能单反相机快门数查询工具推荐 考试报名照片处理工具使用详解
考试报名照片处理工具使用详解